
Spectra Assure Free Trial
Get your 14-day free trial of Spectra Assure for Software Supply Chain Security
Get Free TrialMore about Spectra Assure Free Trial
Machine learning is a cutting-edge predictive threat detection technology. These math-powered classification systems take in object properties, called features, and find correlations between them to proactively detect novel pieces of malware. While the introduction of machine learning technologies represents a significant leap forward for threat detection capabilities, it did very little for detection result interpretability.
Just like the signatures and heuristics before it, machine learning systems are notorious black boxes for human analysts. They offer no glimpses into the underlying logic that led to threat detection or its miss. This lack of detection insights forces defenders to look for answers in other security solutions, hoping that the security stack as a whole would decipher the logic hidden behind these black box convictions.
Security doesn’t need to be this convoluted, nor does it need to be counter-intuitive. Human focus is the missing link that makes security a profession with a high barrier to entry.
Explainable Threat Intelligence, with machine learning at its core, is a unique ReversingLabs concept focused on solving the black box classification problem. Moving away from unexplainable detections requires radical rethinking of how classification engines operate. To be truly analyst-friendly, or human-centered, a machine learning classification must be built from the ground up with explainability, transparency, and relevancy in mind.

ReversingLabs Spectra Analyze (formerly A1000) - Indicators view: Explainable classification with transparent and relevant indicators
Explainability - Machine learning classification must be able to explain its decision with logical and easy to understand verdicts. Regardless of what the classification outcome is, it is based on the analysis that describes the object through indicators. These human-readable descriptions of intent summarize the object behavior. When these indicators are read as a whole, they should describe the detected malware type in a way that is familiar to the analyst interpreting the results. Basing machine learning classification solely on human-readable indicators makes its decisions explainable.
Transparency - Reasons that led to the indicators describing the object behavior must also be transparent. Just like the indicators have to be human-readable and understandable, so must the reasons for their presence. It would be of little value to the analysts if indicator reasons consisted of nothing but byte patterns and hashes. While those are unavoidable in some circumstances, transparency has a goal to increase interpretability. Transparency exposes the rule-based logic behind indicators, and puts emphasis on human-readable object properties. That is why strings, function and symbol names are preferred ways to describe intent. Machine learning relies on indicators to draw its conclusions, and they must be based on verifiable insights.
Relevancy - Even when the object is described through behavior-based indicators, only some of them are going to be relevant to the classification result. When an indicator is relevant for the decision outcome, its relevance can be described as either a strong indicator of malicious intent, or a contributing factor. Those deemed highly relevant are better at describing the detected malware type, while those with contributions considered low are helping solidify the machine learning detection. Relevancy is perhaps the most important Explainable Machine Learning feature. Only by shedding light on the importance of indicators to the final outcome can a classification system instill confidence in its decision making.

Predictive machine learning classification proves itself through detection of malware threats that appeared after the detection models were created. Detection efficacy is measured through the length of time that passed between model creation and novel threat detection. Better detection models require less frequent updates, and therefore their predictive capabilities are effective longer.
Putting predictive models to the test, ReversingLabs continuously monitors their effectiveness in detecting novel malware threats. Being at the frontlines of security means processing huge amounts of data and having the chance to detect threats even before they get name recognition. It is in that kind of environment where predictive detection models shine the brightest. They downsample mountains of data into smaller palatable hills that can be looked at more closely.
It is difficult to choose just one good example where Explainable Machine Learning helped detect malware predictively. The following is merely one of many great examples that show just how well static analysis and machine learning work together. In this particular case, the predictive machine learning model detected a brand new ransomware family.

ByteCode-MSIL.Ransomware.Ravack hiding inside an installation package format
Packing and code obfuscation obscure machine learning vision, as its detection is reliant on spotting malicious behavior. Since packing is often used by clean and malicious software alike, its presence can’t be used to differentiate good from bad. Automated static decomposition removes packing from the equation, and increases the surface area that classification engines have to inspect. Through extraction, embedded content is discovered, and within it malware threats are often found lurking.
There’s no better or simpler way for malware to hide from machine learning models than being deployed through installation package formats. These self-extracting executables are rich with features that machine learning algorithms typically associate with malicious behavior. Due to their nature, installation formats have the potential to change almost any kind of operating system setting. Writing to system folders, downloading components, running arbitrary programs, changing registry and configuration files --- all features found in a typical installation package, and a typical malicious piece of code. Open source installation formats, such as NSIS and InnoSetup, are often abused for malware deployment because of this.
Ravack ransomware, discovered in early March, was distributed inside the InnoSetup installation format. That made the detection on the surface level impossible. But with assistance from automated static decomposition, these installation formats can be inspected in depth. Extraction breaks down the format complexity and provides an actionable overview of its contents.

ReversingLabs Spectra Analyze (formerly A1000) - Extracted files view: InnoSetup package contents
Embedded within the installation package, automated static decomposition finds a single .NET executable. Alongside extraction, static analysis can do one more thing. Installation formats have encoded within themselves the set of instructions on how the installation procedure should be performed. Static analysis decodes these instructions and converts them into a list of system changes. Most important of which, in this case, is the location where ransomware will be installed and the fact that it will be executed right away.
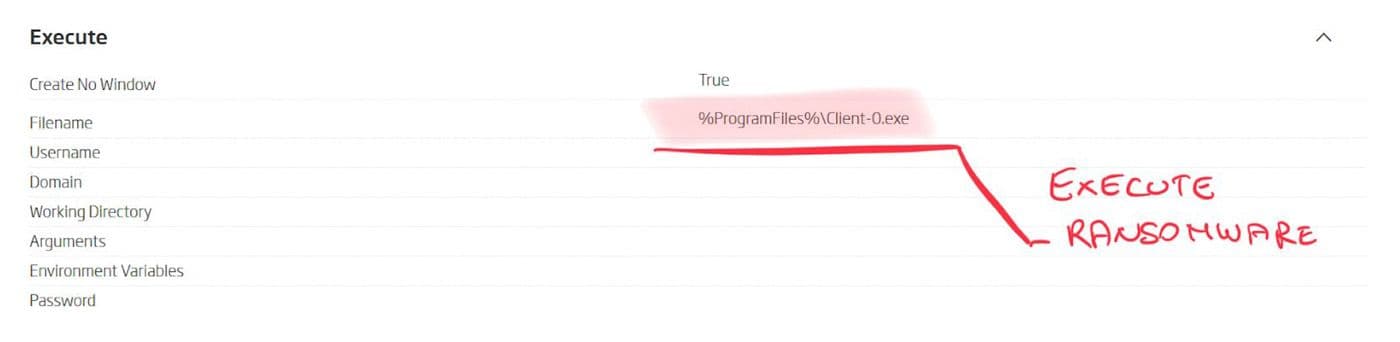
ReversingLabs Spectra Analyze (formerly A1000) - Behaviors view: InnoSetup executes ransomware upon extraction
Machine learning classifications are explainable only if the set of indicators static analysis uses to describe object behavior match with the detection label. Even though the ransomware is obfuscated using the SmartAssembly .NET obfuscator, static analysis still correctly recognizes code intent.

ReversingLabs Spectra Analyze (formerly A1000) - Completed indicators view for ByteCode-MSIL.Ransomware.Ravack
Looking at the highlighted indicator groups, it is easy to confirm that the detection label - ransomware - matches the description they give. The application enumerates files, reads and modifies their content, all with the heavy use of cryptography. These features are also deemed to be highly relevant to the classification outcome, and they describe ransomware as a threat category perfectly.
With the latest addition to Explainable Machine Learning, transparency, even the reasons why those indicators appear are revealed. The application is obfuscated due to the presence of a .NET type PoweredByAttrute which is a marker of the SmartAssembly .NET obfuscator. The presence of each indicator is explained through the underlying data that led to its discovery. Simplified for display purposes, but quite indicative of the code behaviors that the application will exhibit when launched -- regardless of the obfuscation use.
Explainable Machine Learning represents a giant step forward for human-centric threat detection. Only through explainability, transparency, and relevancy can threat intelligence systems be in service of analysts who depend on their insights. Understandable and verifiable conclusions are the key to prioritizing threats and reducing time to respond.
Read our other "explainable" blogs: